
Bringing Vulkan Raytracing to older AMD hardware (Vega and below)

As soon as Bas Nieuwenhuizen mentioned that he was working on support for Vulkan Raytracing in RADV, my curiosity as to whether this feature could be brought to older generations of AMD hardware was peaked.
Yesteryesterday and yesterday I decided to implement some of the missing pieces for exposing Vulkan Raytracing on older generations of AMD hardware, such as Vega, Polaris and the original Navi.
The work is currently available here if you wish to try it at your own risk.

What's new with RDNA 2?
One of AMD RDNA2 (Big Navi)'s selling points was that it supports ray-tracing, but what does that even mean? Compute ray tracers have existed since forever, so what does the new hardware bring to the table? The answer is... very little.
The new hardware brings two instructions, bvh_intersect_ray, and bvh64_intersect_ray to accelerate BVH ray intersection tests. The functionality is pretty straight forward for the most part: address/id of the bvh node and the ray information goes in, ray distance and barycentric coordinates come out for triangles, and a ordered list (by distance) of children that were hit for box intersections. There is a slight bit more to it, as well such as another triangle modes that can give triangle IDs instead of barycentrics (not sure what that's useful for).

This is nothing that can't simply be emulated by hand with a shader, so as soon as Bas had it working on RDNA 2, I started writing something to lower this instruction into the logic behind it for older generations.
The first thing I needed to do was to hook up the SBT descriptor and expose KHR_acceleration_structure for any generation older than GFX10 (Navi).
GFX10+ has different format types and slightly different semantics, but this was pretty straight forward as other descriptors had implementations for older generations also that applied cleanly.
For the rest of this post I will be testing against Sascha Willems' Vulkan Demos. If you try this out for yourself, make sure to apply this PR otherwise it will try to build acceleration structures on the host with device addresses (which doesn't work.)
You'll also need the RADV_PERFTEST=rt RADV_DEBUG=nocache env vars set.
 SaschaWillems
SaschaWillemsGetting Started
Then I started by figuring out what I was working with exactly (I have never written a ray-tracer myself before so this was all new territory for me!).
First, I needed to find out how to tell what type of node we are working with, box or triangle. It's a little bit weird because that information is not passed anywhere into the bvh64_intersect_ray instruction. Turns out, that data is stored in the lower 3 bits of the address of the bvh node passed in. This is fine because the nodes are 64-byte aligned. We can get the type of the node by doing node_addr & 7 and the actual address by doing (node_addr & ~7) << 3.
Going off the documentation, I wrote something that could trigger the ClosestHit shader by testing the type and returning some fixed values. { 0, 0xffffffff, 0xffffffff, 0xffffffff } for box intersections and { 0.1f, 1.0f, 0.5f, 0.5f } for triangles. Excellent, now we have a weird murky blue screen instead of a dark blue screen on the raytracingbasic demo.
Implementing Box Tests
The first type of test I decided to implement was box testing. This is because it would be really easy to see visually if it was working if I kept the triangle intersection returning a fixed value. What I would be expecting is a murky blue quad where the triangle should be.
I started by looking at the box bvh node structure used for building, it is surprisingly simple:
struct radv_bvh_box32_node {
uint32_t children[4];
float coords[4][2][3];
uint32_t reserved[4];
};So I just need to loop through 4 boxes, and find if we hit or not, and order them by distance.
I found some guides online about box-ray intersections and wrote something out in glsl before attempting to translate it to nir ir so I could get some idea as to what I actually wanted to do.
I decided however to not implement the ordering just yet as it is not needed for correctness (yet).
uvec4 child_indices = uvec4(0xffffffff, 0xffffffff, 0xffffffff, 0xffffffff);
for (int i = 0; i < 4; i++) {
vec3 bound0 = (node->coords[i][0] - args->origin) * args->inv_dir;
vec3 bound1 = (node->coords[i][1] - args->origin) * args->inv_dir;
float tmin = max(max(min(bound0.x, bound1.x), min(bound0.y, bound1.y)), min(bound0.z, bound1.z));
float tmax = min(min(max(bound0.x, bound1.x), max(bound0.y, bound1.y)), max(bound0.z, bound1.z));
if (tmax > 0 && tmin <= tmax && tmin <= args->tmax)
child_indices[i] = node->children[i];
}
return child_indices;I implemented this in nir ir and hooked it up to my lowering when the node is for boxes and...
const uint32_t children_offset = 0;
const uint32_t child_size = sizeof(uint32_t);
const uint32_t coords_offset = 4 * sizeof(uint32_t);
const uint32_t coord_size = 3 * sizeof(float);
nir_ssa_def *node_addr = nir_build_node_to_addr(b, args->bvh_node);
const struct glsl_type *vec4_type = glsl_vector_type(GLSL_TYPE_FLOAT, 4);
const struct glsl_type *uvec4_type = glsl_vector_type(GLSL_TYPE_UINT, 4);
/* vec4 distances = vec4(INF, INF, INF, INF); */
nir_variable *distances =
nir_variable_create(b->shader, nir_var_shader_temp, vec4_type, "distances");
nir_store_var(b, distances, nir_imm_vec4(b, INFINITY, INFINITY, INFINITY, INFINITY), 0xf);
/* uvec4 child_indices = uvec4(0xffffffff, 0xffffffff, 0xffffffff, 0xffffffff); */
nir_variable *child_indices =
nir_variable_create(b->shader, nir_var_shader_temp, uvec4_type, "child_indices");
nir_store_var(b, child_indices, nir_imm_ivec4(b, 0xffffffffu, 0xffffffffu, 0xffffffffu, 0xffffffffu), 0xf);
for (int i = 0; i < 4; i++) {
const uint32_t child_offset = children_offset + i * child_size;
const uint32_t coord0_offset = coords_offset + i * 2 * coord_size;
const uint32_t coord1_offset = coord0_offset + coord_size;
nir_ssa_def *child_index = nir_build_load_global(b, 1, 32, nir_iadd(b, node_addr, nir_imm_int64(b, child_offset)), .align_mul = 64, .align_offset = child_offset % 64 );
nir_ssa_def *node_coords_0 = nir_build_load_global(b, 3, 32, nir_iadd(b, node_addr, nir_imm_int64(b, coord0_offset)), .align_mul = 64, .align_offset = coord0_offset % 64 );
nir_ssa_def *node_coords_1 = nir_build_load_global(b, 3, 32, nir_iadd(b, node_addr, nir_imm_int64(b, coord1_offset)), .align_mul = 64, .align_offset = coord1_offset % 64 );
/* vec3 bound0 = (node->coords[i][0] - args->origin) * args->inv_dir; */
/* vec3 bound1 = (node->coords[i][1] - args->origin) * args->inv_dir; */
nir_ssa_def *bound0 = nir_fmul(b, nir_fsub(b, node_coords_0, args->origin), args->inv_dir);
nir_ssa_def *bound1 = nir_fmul(b, nir_fsub(b, node_coords_1, args->origin), args->inv_dir);
/* float tmin = max(max(min(bound0.x, bound1.x), min(bound0.y, bound1.y)), min(bound0.z, bound1.z)); */
/* float tmax = min(min(max(bound0.x, bound1.x), max(bound0.y, bound1.y)), max(bound0.z, bound1.z)); */
nir_ssa_def *tmin = nir_fmax(b, nir_fmax(b,
nir_fmin(b, nir_channel(b, bound0, 0), nir_channel(b, bound1, 0)),
nir_fmin(b, nir_channel(b, bound0, 1), nir_channel(b, bound1, 1))),
nir_fmin(b, nir_channel(b, bound0, 2), nir_channel(b, bound1, 2)));
nir_ssa_def *tmax = nir_fmin(b, nir_fmin(b,
nir_fmax(b, nir_channel(b, bound0, 0), nir_channel(b, bound1, 0)),
nir_fmax(b, nir_channel(b, bound0, 1), nir_channel(b, bound1, 1))),
nir_fmax(b, nir_channel(b, bound0, 2), nir_channel(b, bound1, 2)));
/* if (tmax > 0 && tmin <= tmax && tmin <= args->tmax) { */
nir_push_if(b,
nir_iand(b, nir_iand(b,
nir_flt(b, nir_imm_float(b, 0.0f), tmax),
nir_fge(b, tmax, tmin)),
nir_fge(b, args->tmax, tmin)));
{
/* TODO: Sort here or something for the ordering guarantees
* Just returning in normal order for now */
nir_ssa_def *indices[4] = {child_index, child_index, child_index, child_index};
nir_store_var(b, child_indices, nir_vec(b, indices, 4), 1u << i);
}
nir_pop_if(b, NULL);
}
return nir_load_var(b, child_indices);
Tada! Box testing is working.
I want to clean up the code a bit at some point before upstreaming this, replacing my consts with offsetof/sizeof the actual structures, and adding the ordering etc.
Now onto something slightly harder...
Implementing Triangle Tests
Slightly more annoying as there are so many different ways of doing this.
The bvh intersection instruction returns, for triangle nodes, a numerator for t (distance), the denominator for everything and the numerators for our barycentric coordinates.
I ended up adapting the simplest ray-triangle intersection algorithm I could find which was this Möller-Trumbore implementation which I optimized down to this in nir.
const uint32_t coords_offset = 0;
const uint32_t coord_size = 3 * sizeof(float);
nir_ssa_def *node_addr = nir_build_node_to_addr(b, args->bvh_node);
const uint32_t node_offsets[3] = {
coords_offset + 0 * coord_size,
coords_offset + 1 * coord_size,
coords_offset + 2 * coord_size,
};
nir_ssa_def *node_coords[3] = {
nir_build_load_global(b, 3, 32, nir_iadd(b, node_addr, nir_imm_int64(b, node_offsets[0])), .align_mul = 64, .align_offset = node_offsets[0] ),
nir_build_load_global(b, 3, 32, nir_iadd(b, node_addr, nir_imm_int64(b, node_offsets[1])), .align_mul = 64, .align_offset = node_offsets[1] ),
nir_build_load_global(b, 3, 32, nir_iadd(b, node_addr, nir_imm_int64(b, node_offsets[2])), .align_mul = 64, .align_offset = node_offsets[2] ),
};
nir_ssa_def *v1v0 = nir_fsub(b, node_coords[1], node_coords[0]);
nir_ssa_def *v2v0 = nir_fsub(b, node_coords[2], node_coords[0]);
nir_ssa_def *rov0 = nir_fsub(b, args->origin, node_coords[0]);
nir_ssa_def *n = nir_cross3(b, v1v0, v2v0);
nir_ssa_def *q = nir_cross3(b, rov0, args->dir);
nir_ssa_def *dot = nir_frcp(b, nir_fdot(b, args->dir, n));
nir_ssa_def *u = nir_fmul(b, dot, nir_fdot(b, nir_fneg(b, q), v2v0));
nir_ssa_def *v = nir_fmul(b, dot, nir_fdot(b, q, v1v0));
nir_ssa_def *t = nir_fmul(b, dot, nir_fdot(b, nir_fneg(b, n), rov0));
nir_ssa_def *cond = nir_ior(b, nir_ior(b, nir_ior(b,
nir_flt(b, u, nir_imm_float(b, 0.0f)),
nir_flt(b, nir_imm_float(b, 1.0f), u)),
nir_flt(b, v, nir_imm_float(b, 0.0f))),
nir_flt(b, nir_imm_float(b, 1.0f), nir_fadd(b, u, v)));
t = nir_bcsel(b, cond, nir_fmul(b, nir_fsign(b, t), nir_imm_float(b, INFINITY)), t);
nir_ssa_def *indices[4] = {
t, nir_imm_float(b, 1.0f),
u, v
};
return nir_vec(b, indices, 4);Initially I had some problems with this because I messed up the upper bounds checking and flipped the barycentric coordinates, but I found that out pretty early on and...
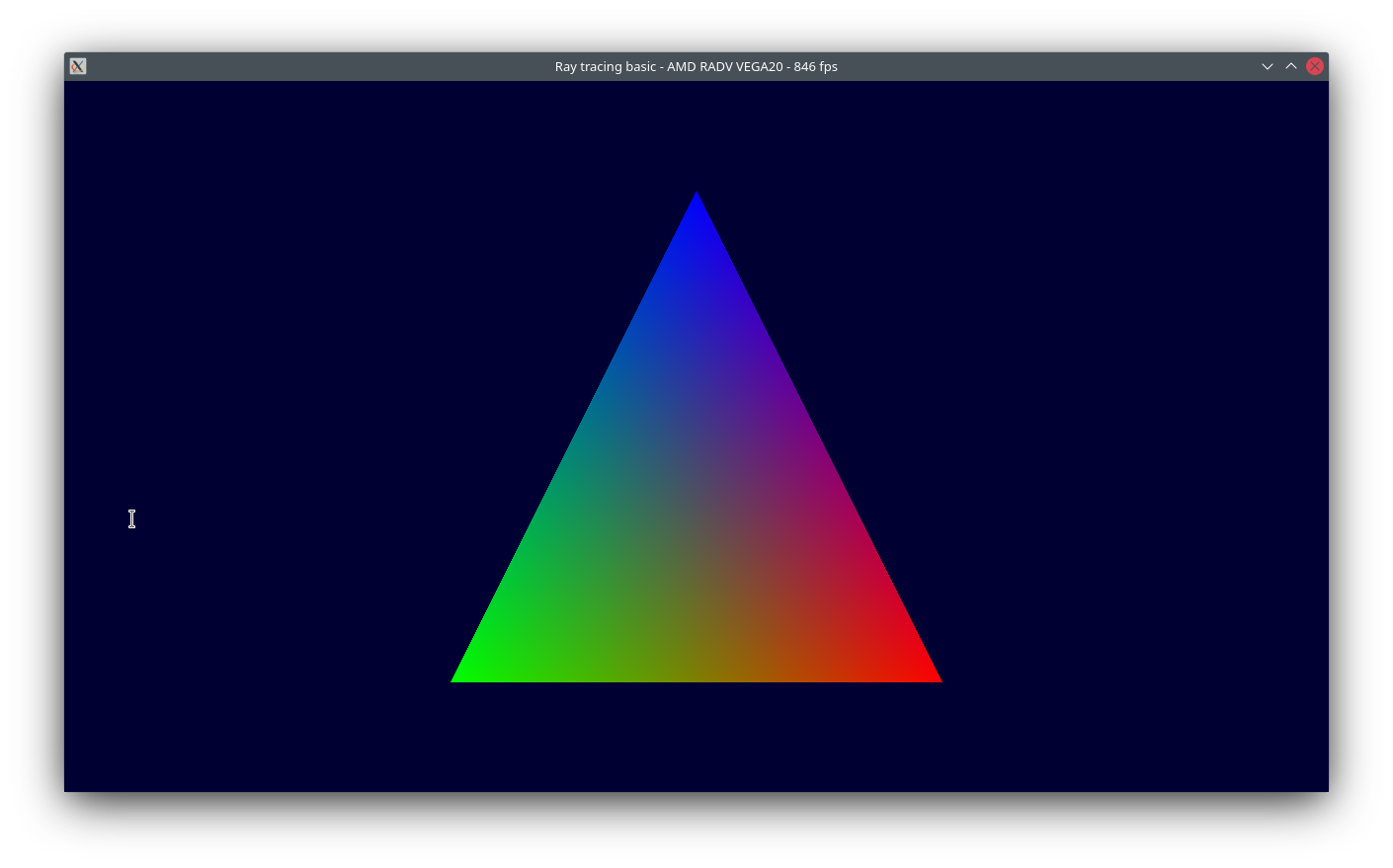
We have a triangle! Nice.
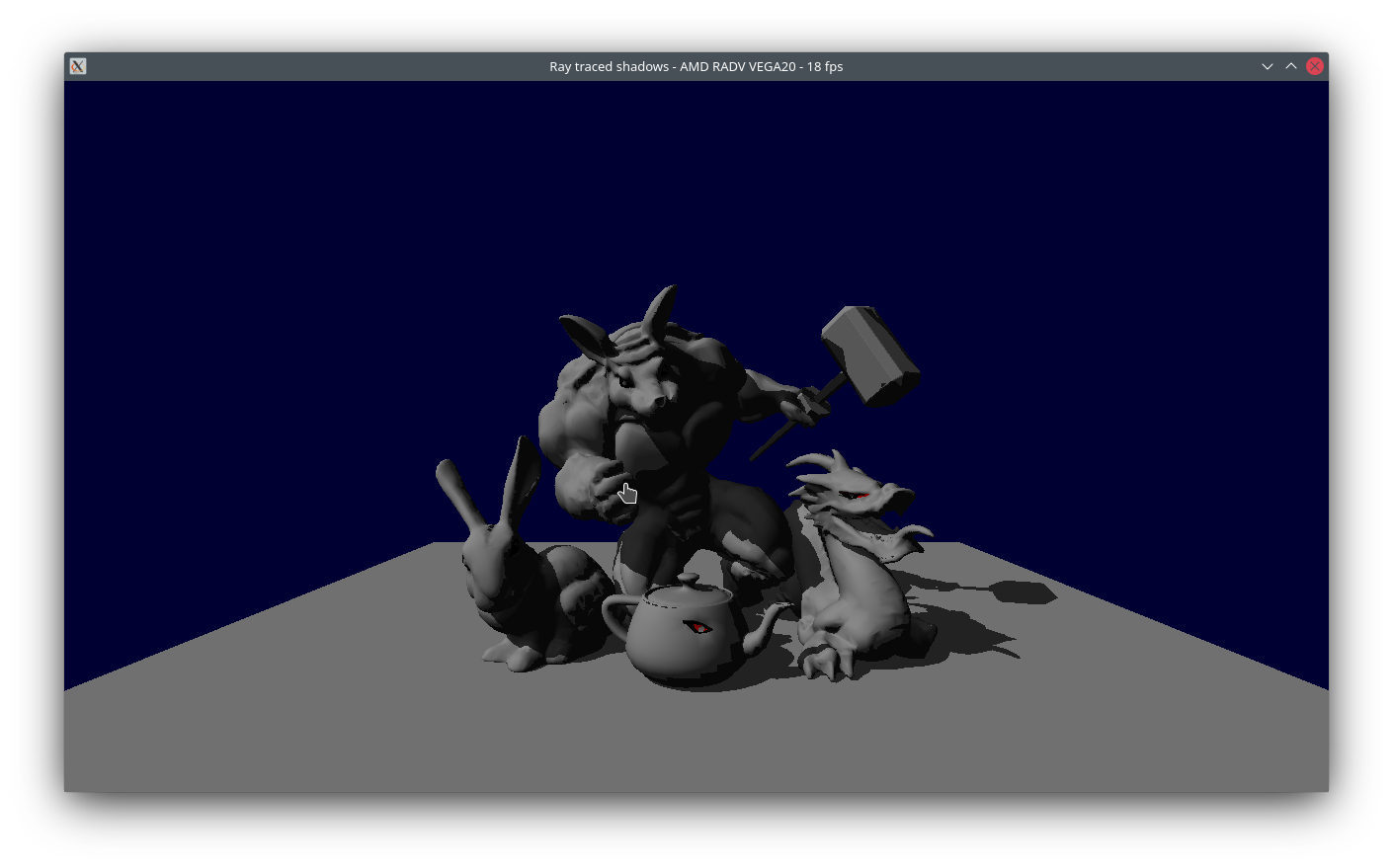
And some shadows!
But hold on, what's going on with the reflections demo?'
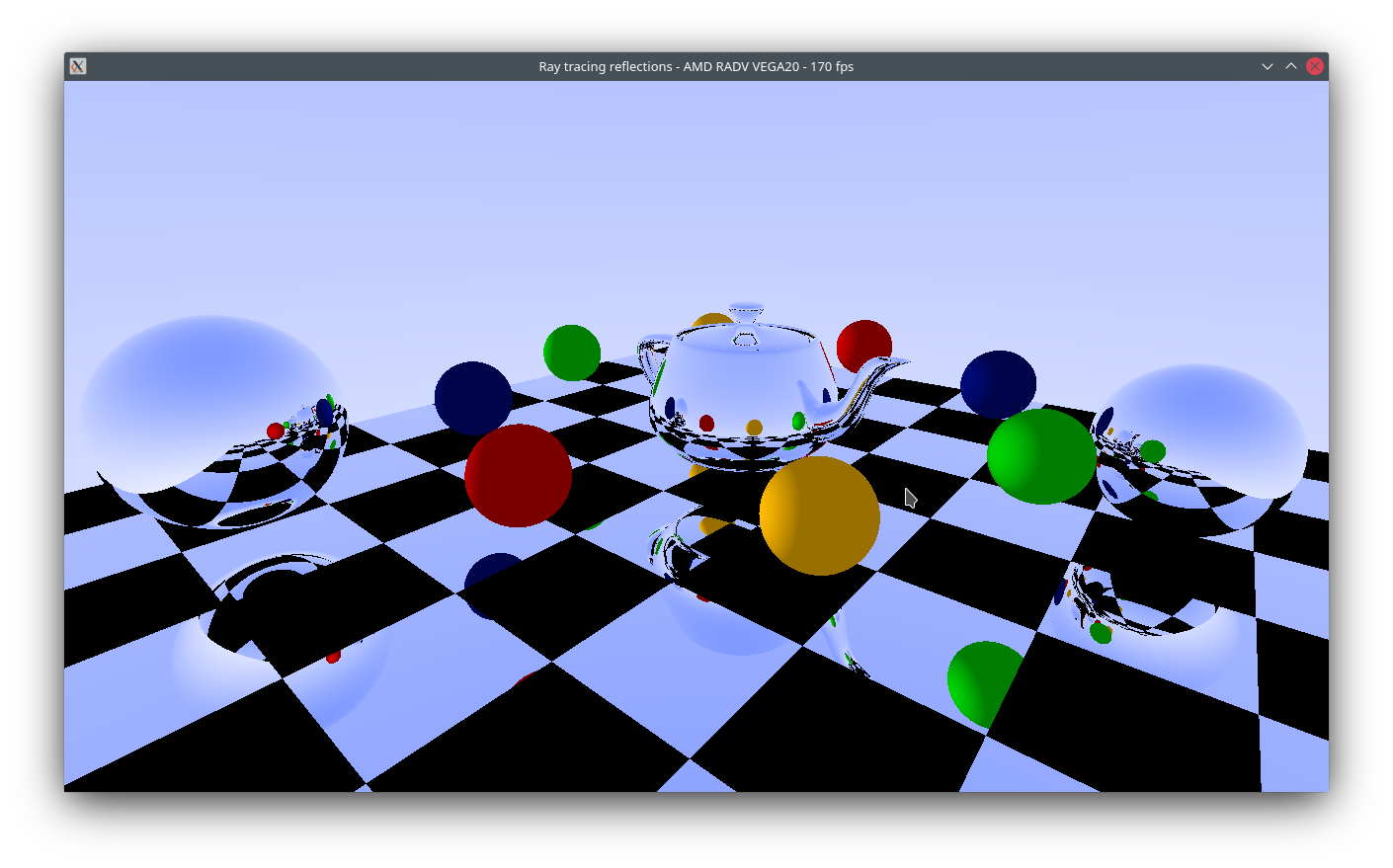
Everything that's meant to be shiny, is just white? How strange.
I spent a long time trying to figure this out, I even implemented a whole new triangle-ray intersection algorithm that is meant to be watertight (that we may end up needing eventually anyway) and still had the same problem... Soooo what's going on?
Turns out, I never checked if t < 0 (where t = distance) in my tests and the tmin check done elsewhere only tests against abs(t). This meant that we were constantly self-intersecting when trying to reflect which was the cause of this issue.
While doing this, I also tried to optimize for the fact that we have both a numerator and divider. The bvh instruction does this to avoid having to do any divides in it's calculation. I ended up with this code.
const uint32_t coords_offset = 0;
const uint32_t coord_size = 3 * sizeof(float);
nir_ssa_def *node_addr = nir_build_node_to_addr(b, args->bvh_node);
const uint32_t node_offsets[3] = {
coords_offset + 0 * coord_size,
coords_offset + 1 * coord_size,
coords_offset + 2 * coord_size,
};
nir_ssa_def *node_coords[3] = {
nir_build_load_global(b, 3, 32, nir_iadd(b, node_addr, nir_imm_int64(b, node_offsets[0])), .align_mul = 64, .align_offset = node_offsets[0] ),
nir_build_load_global(b, 3, 32, nir_iadd(b, node_addr, nir_imm_int64(b, node_offsets[1])), .align_mul = 64, .align_offset = node_offsets[1] ),
nir_build_load_global(b, 3, 32, nir_iadd(b, node_addr, nir_imm_int64(b, node_offsets[2])), .align_mul = 64, .align_offset = node_offsets[2] ),
};
nir_ssa_def *v1v0 = nir_fsub(b, node_coords[1], node_coords[0]);
nir_ssa_def *v2v0 = nir_fsub(b, node_coords[2], node_coords[0]);
nir_ssa_def *rov0 = nir_fsub(b, args->origin, node_coords[0]);
nir_ssa_def *n = nir_cross3(b, v1v0, v2v0);
nir_ssa_def *q = nir_cross3(b, rov0, args->dir);
nir_ssa_def *dot = nir_fdot(b, args->dir, n);
nir_ssa_def *dot_sign = nir_fsign(b, dot);
nir_ssa_def *dot_abs = nir_fabs(b, dot);
nir_ssa_def *u = nir_fmul(b, dot_sign, nir_fdot(b, nir_fneg(b, q), v2v0));
nir_ssa_def *v = nir_fmul(b, dot_sign, nir_fdot(b, q, v1v0));
nir_ssa_def *t = nir_fmul(b, dot_sign, nir_fdot(b, nir_fneg(b, n), rov0));
nir_ssa_def *cond = nir_ior(b, nir_ior(b, nir_ior(b, nir_ior(b,
nir_flt(b, u, nir_imm_float(b, 0.0f)),
nir_flt(b, dot_abs, u)),
nir_flt(b, v, nir_imm_float(b, 0.0f))),
nir_flt(b, dot_abs, nir_fadd(b, u, v))),
nir_flt(b, t, nir_imm_float(b, 0.0f)));
t = nir_bcsel(b, cond, nir_fmul(b, nir_fsign(b, t), nir_imm_float(b, INFINITY)), t);
nir_ssa_def *indices[4] = {
t, dot_abs,
u, v
};
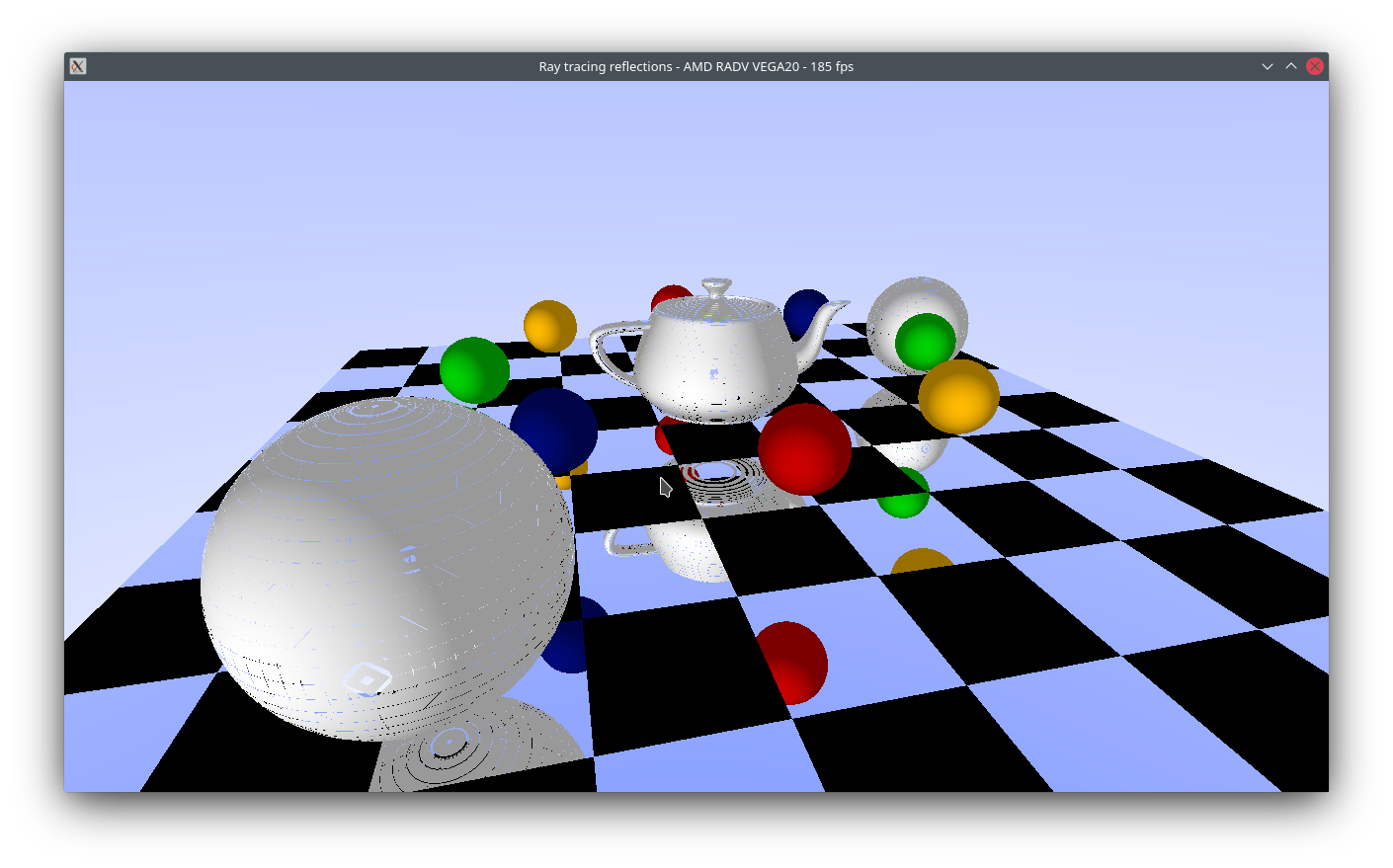
return nir_vec(b, indices, 4);And...
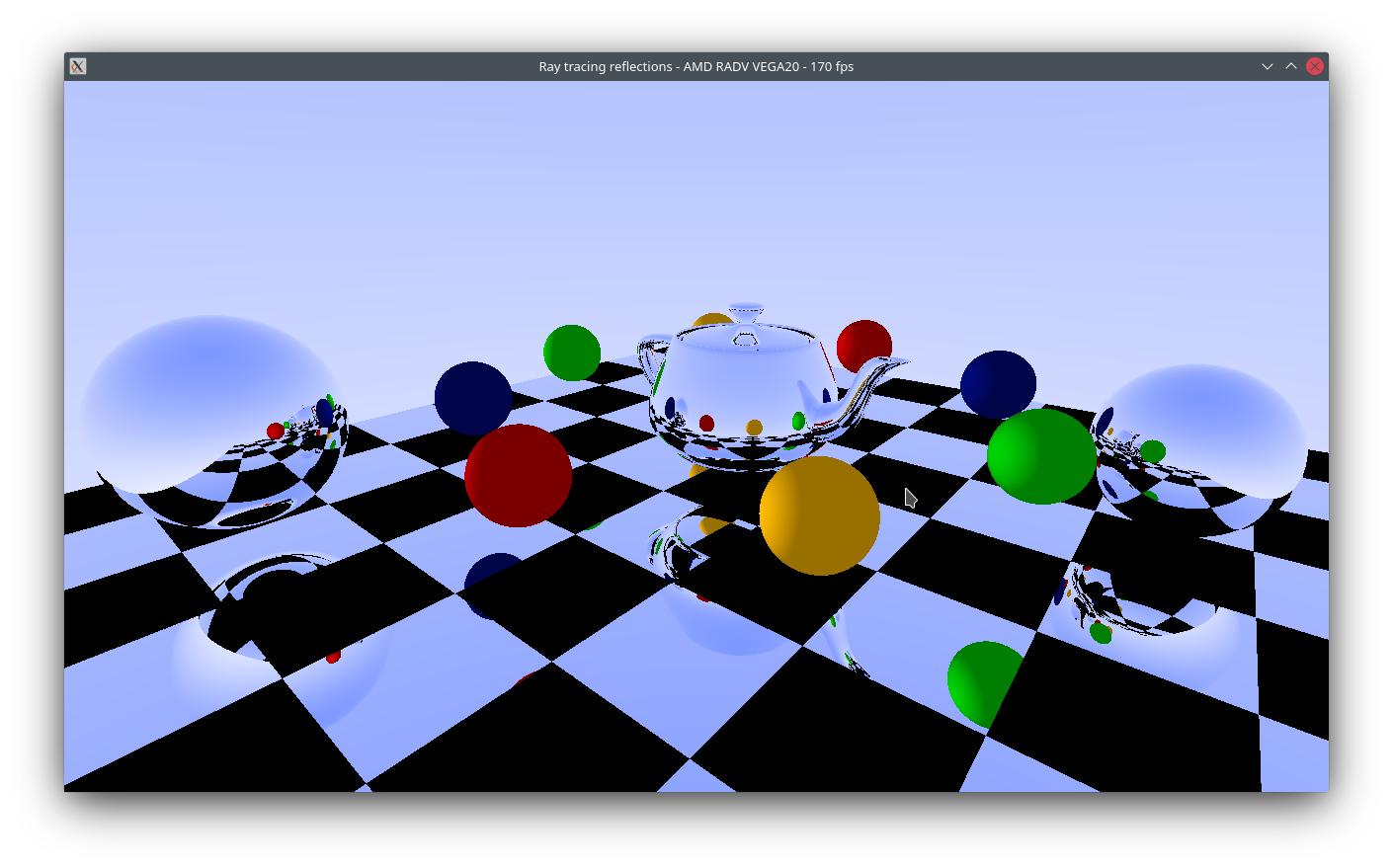
Ayyy we got some nice looking balls and teapots now. Nice.
What's next?
Well, these demos are really all that runs with it right now. I am waiting for the rest of the ray-tracing features to be implemented so that I can try more demanding apps such as Quake 2 RTX, Control with VKD3D-Proton and the dreaded Vulkan CTS.
Time will tell whether I need to revisit the triangle intersection algorithm for the watertightness tests in Vulkan CTS. I have an implementation using both this modified Möller-Trumbore and the Watertight Ray/Triangle Intersection paper in the repo right now. Hopefully at least one of them will pass the tests... 😅
Conclusion
Vulkan raytracing on older generations of AMD hardware is possible and there is no technical reason to not expose it. I am not sure how performant it is going to be yet by the end of everything but it should at least be possible to eventually run games with it.
If I am honest, I see no reason why AMD should not expose this in their open/proprietary drivers, even if it runs bad. In my opinion it would be a better marketing strategy to show a solid performance delta in ray-tracing performance from say Vega/RDNA1 -> RDNA2 rather than artificially locking out customers with older GPUs.
The primary use of something like this would be getting more test cases for RADV/ACO and VKD3D-Proton. I don't have an RDNA 2 card yet and probably won't for some time so any ray-tracing tests in the Vulkan CTS or VKD3D-Proton when I make changes and re-test would be skipped. It is possible that silent regressions could be introduced because of this, which is why exposing new features on older hardware is important.
Adendum rant about AMD's official drivers
It is really sad to see how little AMD cares about Linux as a platform for Vulkan.
On Linux, it took them 5 months since the ray-tracing spec-launch to be bothered to rebase and release their proprietary driver with ray-tracing support – and we have still yet to see their open-source variant, AMDVLK have any support.
On Windows, this was day 1.
AMDVLK and AMDGPU-Pro are pretty much worthless as targets for developers. Waiting between 3-months and half a year for a release with new fixes/features is a complete joke for anyone wanting to ship a game or really anything.
Not to mention, that they basically locked every RDNA2 owner on Linux out of a flagship feature that they paid for and provided little public documentation on the ray-tracing instructions in the ISA – all the above information on the instructions was from Bas' reverse engineering work on the BVH node formats and return values.
Please do better in future.